说话人分割 (Speaker Segmentation)
说话人分割使用说明
可以理解为「谁在什么时候说话」:在一条录音里,用两种颜色在时间上标出说话人甲、说话人乙的片段(可多次交替)。与
对话分析(已带 author+时间+正文的气泡)不同,这里只有波形区段;与
声音事件监测 的交互类似,但标签语义是说话人而不是泛化「事件」。
标注核心作用
- 两类标签常对应两个说话人,颜色用强对比(如亮绿与深绿)减少混淆;
- 可连续多段、交替标同一说话人,以覆盖多人轮流发言的长音频;
- 为下游 diarization、说话人相关 ASR 或质检提供时间掩码级标注。
基础操作步骤
- 听全段,熟悉每人嗓音与交替节奏,明确「说话人一 / 二」在规范中的指代;
- 选择当前要标的说话人标签;
- 在波形上拖选该说话人发声的起止;换人时切换另一标签,重复至覆盖需标注的区间;
- 必要时微调区段边界,与项目边界规则一致后提交。
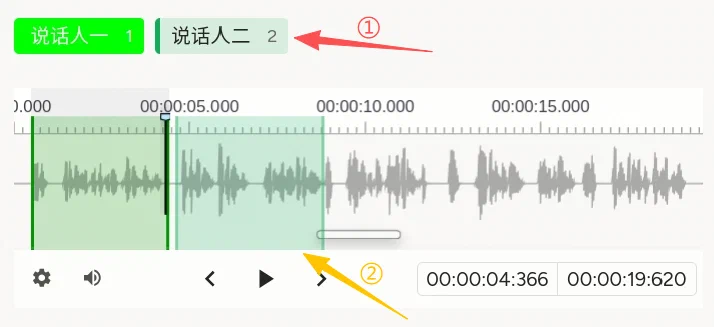
说明:截图中①示意选中的「说话人二」等标签;②示意波形上对应该说话人的区段。
注意事项
data.audio须可访问;示例使用与会话类示例相同的conversation.mp3时,路径按部署实际替换;- 说话人超过两位时,请增加
Label并区分颜色与培训说明; Labels上zoom、hotkey是否生效以平台为准,参见 声音事件监测 中同类说明;- 若需逐句转写或话轮级情感,可叠加 使用片段的自动语音识别 或 对话分析 等流程。
模板预览
模板配置
完整代码块
<View>
<Labels name="label" toName="audio" zoom="true" hotkey="ctrl+enter">
<Label value="说话人一" background="#00FF00"/>
<Label value="说话人二" background="#12ad59"/>
</Labels>
<Audio name="audio" value="$audio" />
</View>配置代码说明
以上代码为「说话人标签 + 音频」,与
声音事件监测 结构一致,仅 Label 文案与色值不同。
1、标签:Labels name="label" toName="audio" 指定区段类型为说话人;background 为十六进制颜色。
2、音频:Audio name="audio" value="$audio" 从任务数据的 audio 字段加载。
示例数据(简要)
{
"data": {
"audio": "/static/templates/project-samples/conversation.mp3"
}
}说明
- 代码可直接复制到标注配置文件中使用;
- 请将路径替换为实际上传或静态资源中的音频地址。